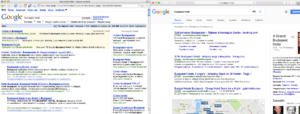
I have just come across an old screenshot of a Google result page while tidying up my files, and I just could not resist comparing it to a contemporary one. Wow, those were the times when you had at least a chance to get on the screen with SEO for popular keywords!
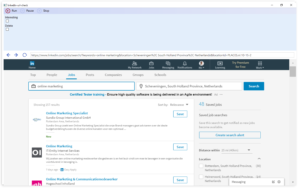
These two screenshots showing the results for the very lucrative keyword combination: ”hotel budapest”, albeit in Hungarian, clearly illustrate how Google’s search engine evolved over the years. While you might spot first some web design related changes, it is more interesting to look behind the surface and discover the substantial changes and tendencies which have a great impact on our daily online marketing activities.
No organic results above the fold
While the old screenshot shows four non-paid search results, occupying almost the half of the screen real estate devoted to displaying results, the more recent screen capture has no ordinary search results above the fold, not even on bigger screens with full HD resolutions.
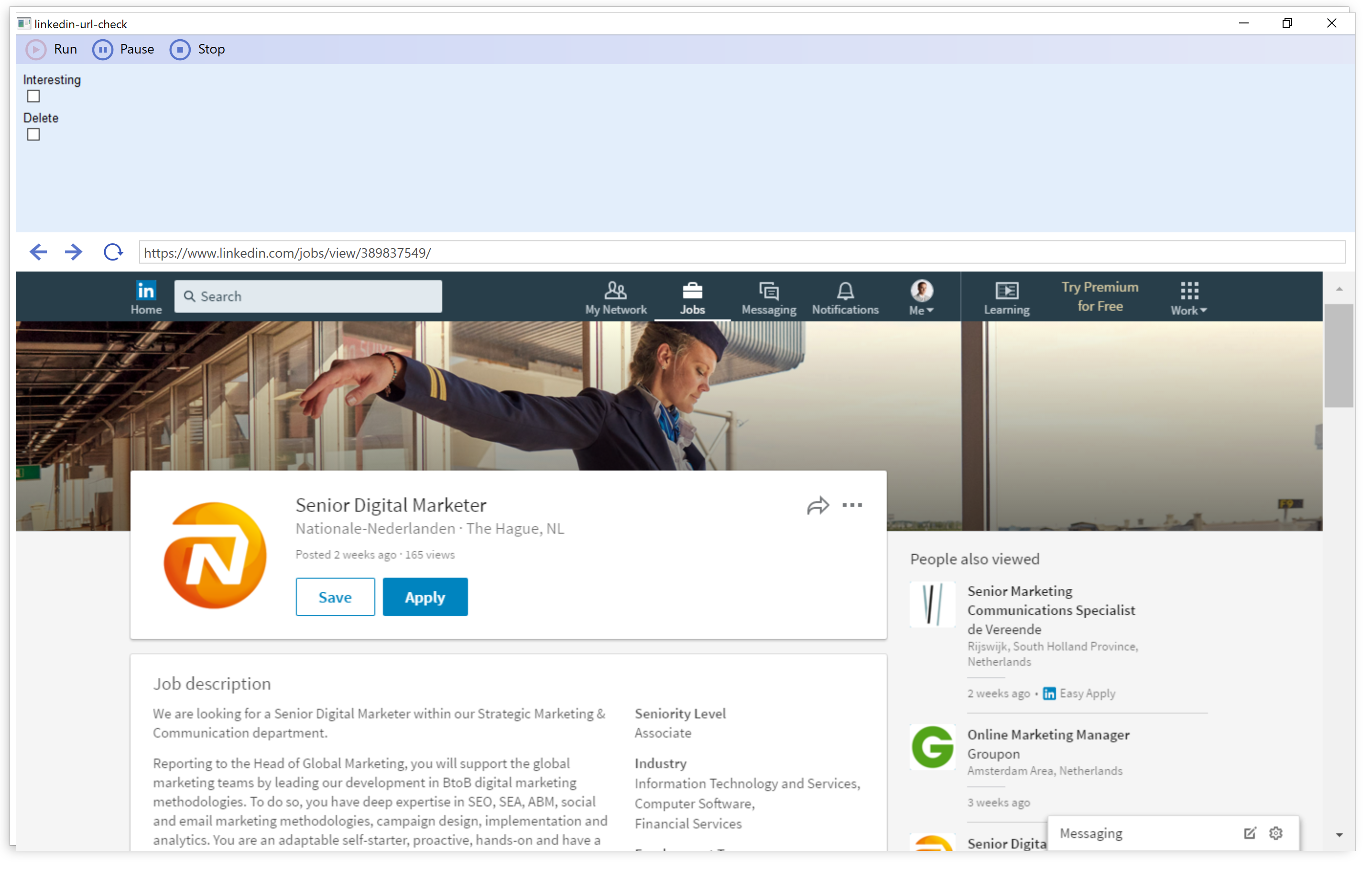
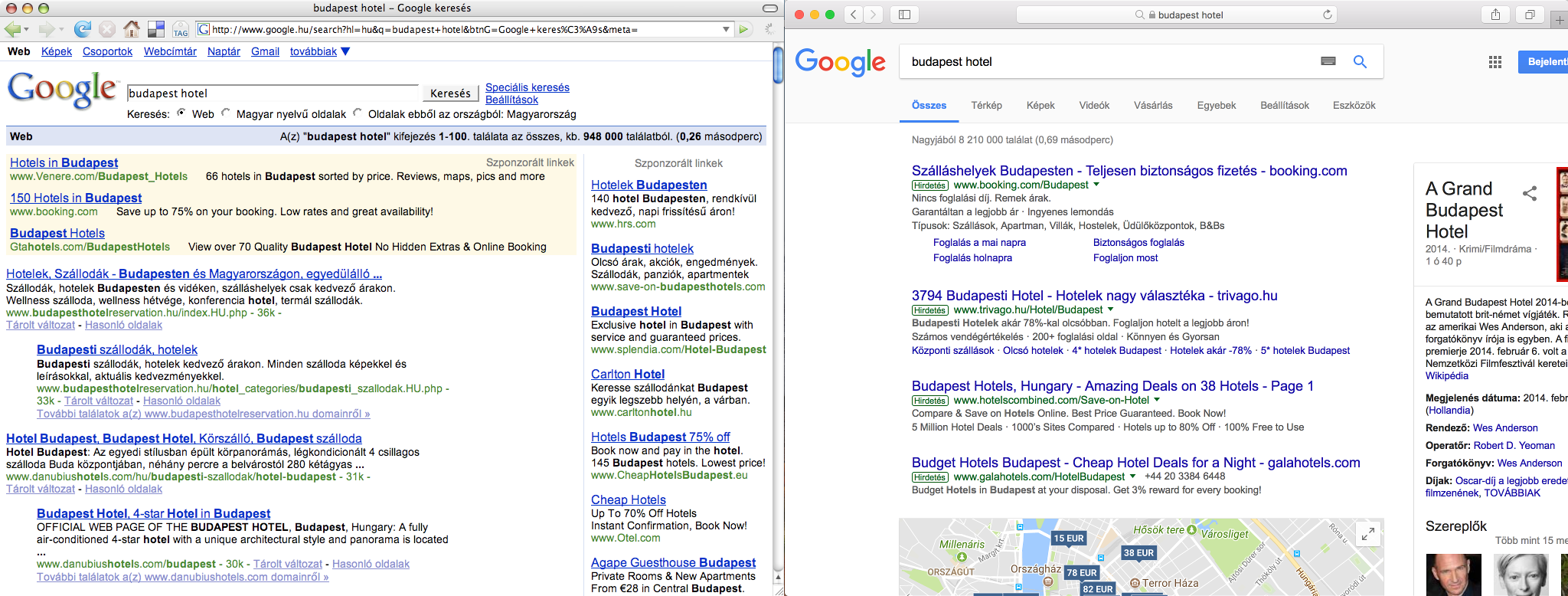
During those good old days, if you were clever enough, you could get a considerable exposure in Google search results, while nowadays you have to rather rely on paid online campaigns, just because otherwise you cannot bring your message before the eyes of your audience on the most popular web pages. On the above screenshot, you can observe how the paid results, a knowledge panel on the side, and the map-based hotel search interface push down the first organic search results way below the fold. Meanwhile, in the old screenshot below, you can spot non-paid result snippets of an old-school hotel booking/aggregating site and a website of a local hotel aptly named “Hotel Budapest”.
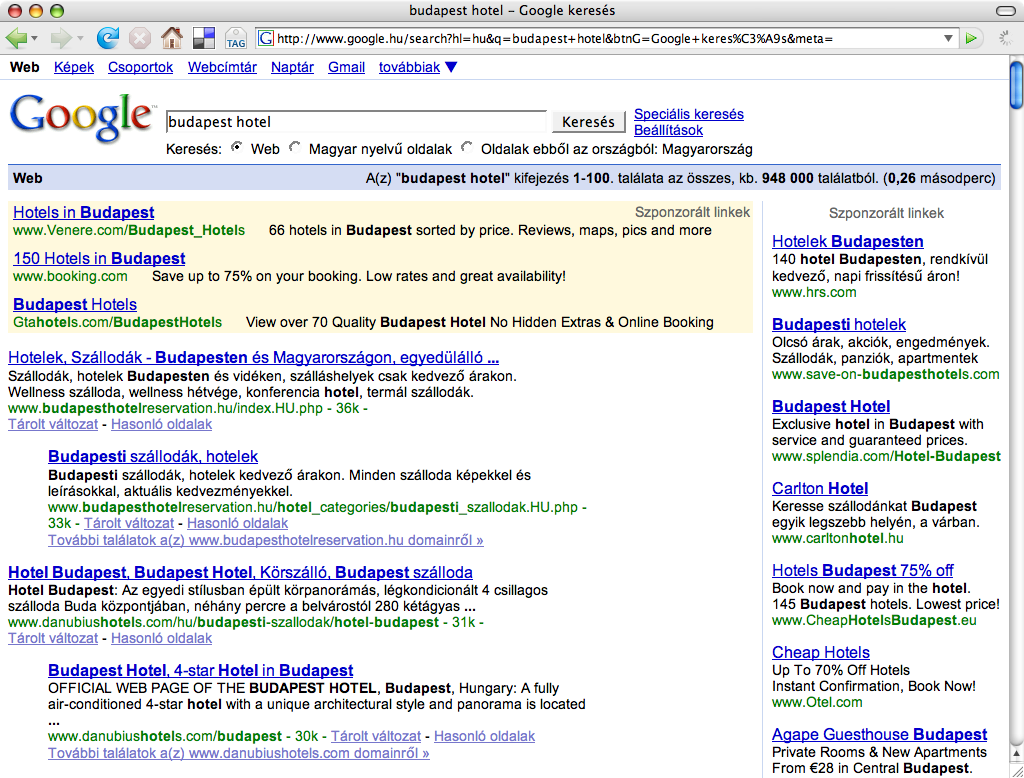
By the way, these webmasters of these first-generation hotel listing/booking pages were among the first ones who were actively doing SEO in Hungary. These sites had been optimized quite frequently by the owner of the property, heavily relying on automated mass link exchange schemes and other, now obsolete, if not counterproductive techniques. They had been wiped out a couple of years ago by a Google algorithm update, way before booking.com and Airbnb started new chapters in the history of online booking.
Google wants to keep users in its walled garden
Although Google’s robots still do not create content, the tendency is clear, just as it was obvious ten years ago too: more and more web content is to be scraped, processed and displayed in a structured format on Google’s own web pages, thus more and more answers are given on the search result pages itself, therefore the content creators are rewarded with fewer and fewer clickthroughs by Google.
You can observe how the hotel offers are listed on a map, how the different prices from the booking portals and the hotel web pages are blended in search results, and how the whole thing is enriched by user reviews and other additional information hosted by the Google My Business service.
It can be easily seen that this ”movement” provides a more seamless experience for the search engine users but also means a lot of drawbacks for the webmasters aiming for getting organic, that is, free traffic from one of the most popular websites of our time.
Conclusion
As big online platforms, such as Google and Facebook, are trying to increase their revenue year by year, less and less free slots are to be available for webmasters, and more and more is to be paid if someone wants to get traffic from these huge sites.
The other phenomenon related also to the constant need of generating more profit is that these online platforms are increasingly capturing others’ content, incorporating them into their services, that is, instead of conveying traffic to the content sources, they will try everything to keep their users close to their ad placements while they consume the third-party contents.
Some more tidbits
It’s also funny to see that while a couple of years ago there was only 948 000 results reported, nowadays there are approximately 8 210 000 results estimated – almost ten times more.
This might be the reason for a ”slower” result generation time: instead of 0,26 seconds, it took almost three times longer, a whopping 0,69 seconds. 🙂
The new results page just does not fit on a 1024 pixel wide screen anymore — a screen resolution commonly used by web designers as the minimum width ten years ago.
The knowledge panel providing in-depth information about a movie titled ”The Grand Budapest Hotel” among the contemporary results indicates that Google is not quite sure about your search intent when you just type ”budapest hotel”. If the big G is not sure what you are looking for, then there might be a considerable amount of search volume for the movie too — in comparison to the volume of the ordinary hotel searches.