Six years ago, when we were pretty much in mass link building and link directory submissions, this script literally substituted a half-time employee, as it helped us to automatically check the presence of our links on various link directory sites. Although there are a couple of link checkers covering the use case when you know the specific URLs where to look for your links or an entire site is to be crawled in search of a link, but my directory link checker script does something different. You just have to enter the list of link directory domains where your links have been submitted and this script just tells you if those links have already been approved or not. This proved to be a very handy script for creating link building reports for our clients.
My very first web automation script
It took more than a week to write this script, and finally, when it was ready, It took again a week to re-write the whole thing from the ground up again. Way back then the challenge was that in many link directories you would never know the URL of the subpage where your submitted link showed up once it had been approved, so the only thing you could do is to check the mailboxes used for link building and go through the emails which were about submission approvals, plus open the sites and checking whether the links are already online – all of this made by hand. Obviously, gathering the list of successful submissions meant a lot of manual labour.
(The link submission process itself was already highly automated as we had been using a semi-automated link directory submission software, which meant a good compromise between speed and accuracy —as before submitting the links, we could choose the best category by hand, or enter appropriate data in a couple of directory-specific submission form fields.)
The logic of the link checking process
Using search engines to find the links
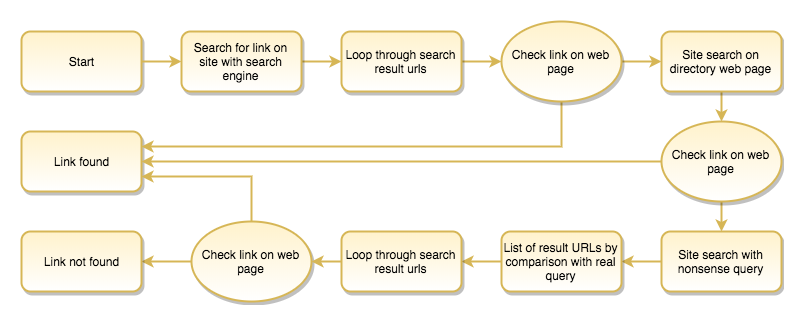
As the above, simplified diagram outlines, the script first scrapes the search engine search results restricted to the link directory domain, using search expressions like:
promoteddomain.com site:linkdirectorydomain.com
It crawls all the URLs listed as a result for these queries and if a link is found there, it logs the data of the successful link submission, loads the following link directory domain name and starts the process again.
Searching with the site search function of link directories
But if it fails to find traces of the submitted links with a web search engine (for instance Google or Bing), then it attempts to make a site search on the link directory page itself. As some directories are already linking the promoted domain from the search result page, the script might already succeed here. But if not, it starts to loop through the subpages listed as search results, loading each of these pages and checking the presence of the outgoing links pointing to the promoted domains.
Figuring out which internal links are search results
I could have created a database for each link directory, specifying the necessary parameters for doing a site search and evaluating it. Figuring out these parameters for each directory site, such as the search query URL schema and the regular expression to identify which internal URLs are search results on a site search result page. In this case the script could quickly and efficiently check the presence of links in the already known link directories, but the problem was that we had been constantly adding a lot of new directories to our database, plus as we had been doing link building in many different languages, it would have meant a lot of extra work to create and maintain such a database of parameters for thousands of link directories.
Therefore, I opted for a slower, brute-force solution which meant at least one extra query: searching for something nonsense, random string (such as the date and time), which ensured that no search results were displayed for it. Comparing the internal links of this with the normal search result pages, the difference shows us which internal links are search results, and which are other navigational, e.g. header or footer links of the page template.
The detailed link checking process
The below process seems to be a lot more complicated than the previous one, but there are good reasons for it. Mostly because I wanted to include certain modules only once, and re-use them as much as possible so that later on I could easily add improvements to the process. Interacting with many different kinds of websites is always a tricky issue, something you have to constantly refine. For instance, your regular expression does a perfect job on hundreds of sites but eventually fails on a specific web page.
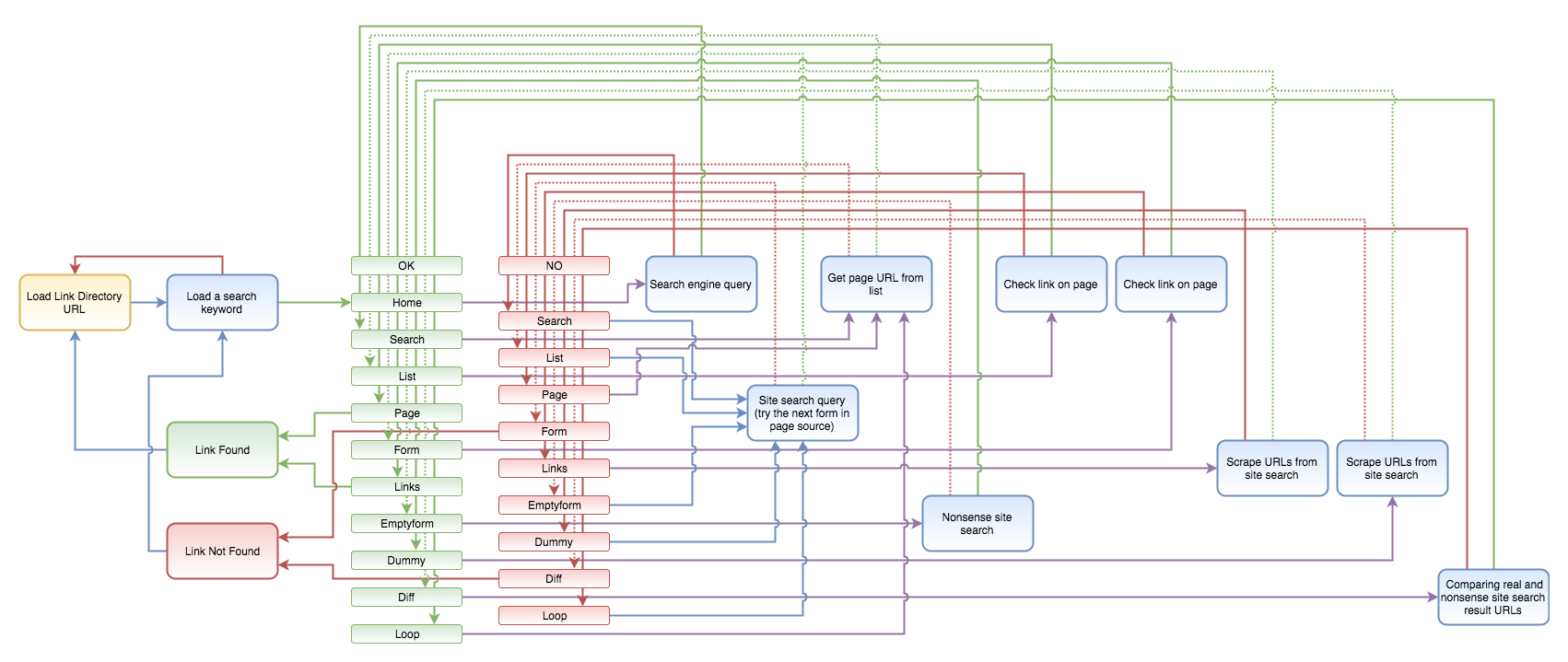
Identifying search forms
On the other hand, there is a second trick apart from figuring out the search result links, that is how to find out which form is a search form, and what should be done to submit that search query? Here again, I opted for the brute-force solution: the script enumerates all the forms on the link directory home page and tries to submit these forms using search queries like the promoteddomainname.com or {specific keyword combinations used in link submission texts}. If upon submitting the first form, there will be no results —just because the submitted link is not yet listed in the directory— it attempts to submit the second form, even if it is a login form.
Attempting to submit forms
Similarly, if the submit button can be easily found, the script attempts to submit the form by either clicking on other elements where chances are high that it could submit the search form with or emulating the keystroke of the enter button while the cursor is in the search field, etc.
Loops
As you can see, there are a lot of loops in this process given the brute-force nature of the script. First, it loads the link directory to work with, then it loops through the search keywords you will use to find traces of your submitted links (at least there should be two expressions: the promoted domain name itself and a specific brand or a very specific keyword combination you have included in any link submission text you have spun —something to take into consideration as early as setting up your link submission project.)
Controls
There are subsequent steps like home, search, list (not always a meaningful nomenclature, but nevermind). In every step, a different module is called. If the module exits with success then it returns to the OK branch, if not, then to the NO branch. Depending on the value of the step variable, these two branches point to different modules, that is if it could not succeed with one search method then it goes on to try another one.
Your very own free link checker script
The script has been created with ZennoPoster, a powerful web automation tool, so first, you have to get and install this wonderful piece of software. Then click here to download the script.
Feel free to use, adapt and re-share it under the following terms: https://creativecommons.org/licenses/by-sa/4.0/ and please point a link to this page or to www.jaroli.hu.
Notes
If you already know ZennoPoster and/or find some of the solutions quite odd: Well, the script was originally written with ZennoPoster 3 way back in 2012, but soon afterwards an entirely rewritten ZennoPoster was brought to the market, with a lot of new concepts and many advancements in debugging, therefore I had to rewrite the entire script, but I just wanted to keep the changes to the minimum, like using lists instead of files or using switch boxes instead of a series of if boxes: as you can observe in the below screen capture which shows the imported Zenno3 script along with the recently rewritten one.
